25/06/2014 How bad are small triangles on GPU and why?
RSS Feed ~ Comment: by email - on Twitter ~ Share: Twitter - Facebook - Linked In - Google+ - Permanent link
Small triangles is bad for performance and this is not something new. In this post, we are just looking at some numbers to quantity these bad performance.
We are using a simple scenario where the framebuffer is filled with tiles of variable sizes, each tile being composed of two triangles and no tile is overlapping another. The vertex shader only transform the vertices and the fragment shader is a pass through shader. This scenario could be seen as a best case scenario, if not best, it's close to a best case. Nevertheless, the results show horrifying performances on small triangles.
Following, two images showing examples of rendering used for these tests.

First test with squared tile sizes and a full frame tile
In a first test, we are filling a 1080p framebuffer using tiles from 1 by 1 to 128 by 128 and even using a single pair of triangle to fill the entire framebuffer. (Going that way, a single triangle makes better sense for the hardware but it was enough for illustrate our scenario).
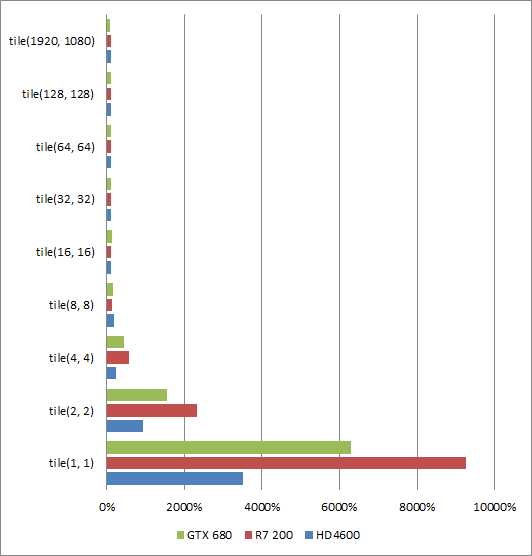
The first conclusion is that filling the framebuffer with anything larger than 16 by 16 tiles have no effect on the GPU performance for any desktop vendors at least for the primitive rasterization/fixed function point of view.
The primitive minimum size in pixels is pretty much the same for all vendors. Covering 8 by 8 pixels with two triangles starts to have a significant impact on performances but it's still acceptable as not a performance cliff.
Interestingly, Southern Islands seems to be the least affected architecture by 8 by 8 pixel tiles. Beyond that point, Southern Islands architecture performance cliff-ed faster than the others architectures.
Haswell behaves the best with small triangles. "The best" is still a performance cliff as basically Haswell, Kepler and Southern Islands are about 10x, 15x, 20x slower than optimal performance respectively.
Does the shape of the triangles really matters?
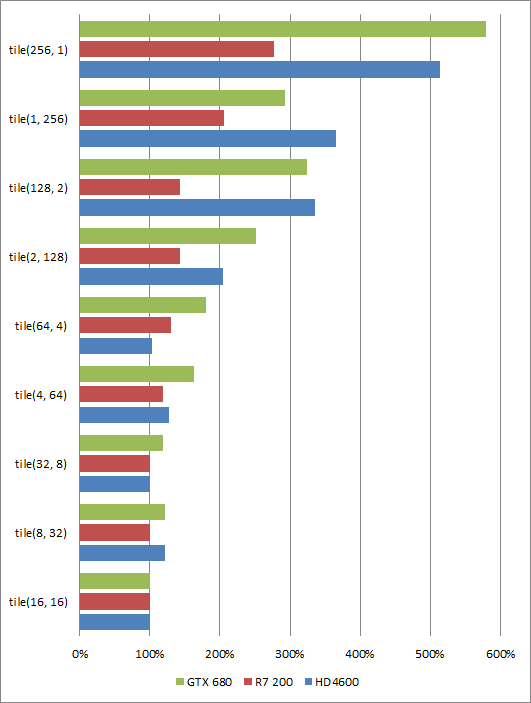
Yes, the shape matters but the good new is that equilateral triangles is generally better for all vendors.
It's funny how different are the performance characteristics between 256 by 1 and 1 by 256 for example. However, this is nothing really surprising considering the rasterization patterns of the GPU architectures that is obviously not designed to be somewhat anisotropic.

What about sub-pixel triangles?
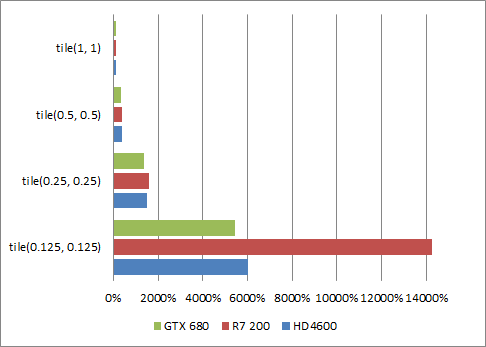
It's only getting worse! In this test the framebuffer size is only 320 by 240 because at 1080p implementations would all time out at 0.25 by 0.25 or 0.125 * 0.125 tile sizes.
The performance cliff is exponential
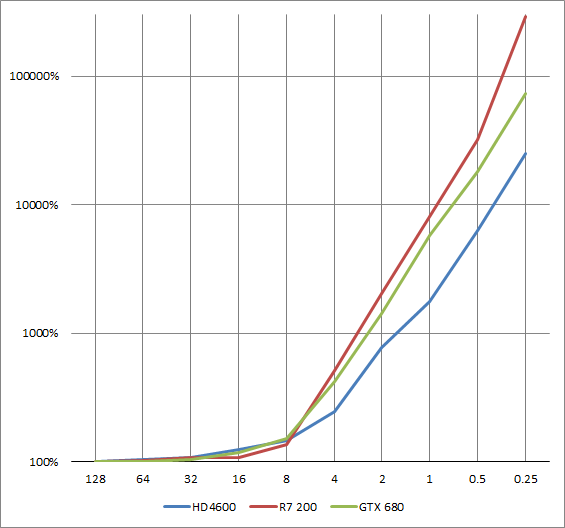
This last drawing is to highlight that the performance cliff is about exponential.
Conclusion
Why such performance cliff? Because GPUs work at varius granularities that is always larger than 1x pixels.
First, there is the quadpixels (block of 2 by 2 pixels) that are used to compute the derivatives. The derivatives are used for the explicit fragment shader derivatives but also to select the correct mipmaps while filtering as shown in the following code that can be wired in the texture units.
- float textureLevel(in sampler2D Sampler, in vec2 Texcoord)
- {
- vec2 TextureSize = vec2(textureSize(Sampler, 0));
- float LevelCount = max(log2(TextureSize.x), log2(TextureSize.y));
- // Access neighbour values within the quadpixels to return the derivative
- vec2 dx = dFdx(Texcoord * TextureSize);
- // Access neighbour values within the quadpixels to return the derivative
- vec2 dy = dFdy(Texcoord * TextureSize);
- float d = max(dot(dx, dx), dot(dy, dy));
- d = clamp(d, 1.0, pow(2, (LevelCount - 1) * 2));
- return 0.5 * log2(d);
- }
Equally important or even more important: the primitive rate. For example, Tahiti is capable to process two triangles per clock. However, each triangle is effectively sliced into multiple primitives within 8 by 8 pixel tiles. If a triangle overlap two tiles, the triangle requires two primitives. If a triangle overlap only a single pixel, then the budget for the other pixels in the 8 by 8 tile is wasted as only a single primitive can be scanned per cycle per tile.

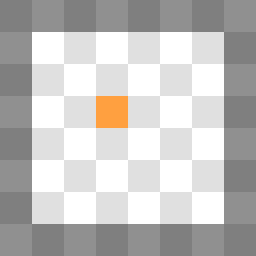
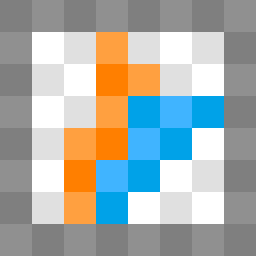


Considering these numbers, the felling that tessellation is the biggest waste of GPU area space since the geometry shader might be a little too quick. It's a waste because engines don't really use tessellation however it provides an effective way to control the size of the primitives on screen. Is the current OpenGL 4 / D3D11 hardware tessellation good enough? I don't have that answer.
In the meantime, if we want some good primitive performances, let's set the minimum target to about 8 by 8 pixels per triangles on screen.
The source for these tests in available in the staging of the OpenGL Samples Pack 4.4.3 branch.