09/06/2010 Releases oriented development model with Git
RSS Feed ~ Comment: by email - on Twitter ~ Share: Twitter - Facebook - Linked In - Google+ - Permanent link
Let's define a working process!
In this article, I am going to present the development method I am using for G-Truc Creation projects. What's the 'releases oriented development model'? Just a name I came up with, just like the development method I am using. Please, this is not about taking things for granted but about giving some thinking material on the working process. From as long as I started programming, some friends will remember how I spent my time to repeat the importance of project releasing.
The only thing that matter, it's the release! Not only once, we need to release twice because as long as we manage to release twice, we will be able to release more.
This is quite a passionnate idea quite disconnected from any reasons but I quite believe it remains a base idea for how I work and how I want my way of working to evolve. One of my assumption is that the way we work ('how') affect the result just like what we actually do. The longer the project lives, the higher the working process matter. If the project is meant for one release and then being through away then I would say "who cares about the working process?".
- Allow to release anytime
- Allow to maintain old versions and sub-versions of a project
- Allow testing multiple platform simultaneously
- Allow an easy support of a new platform
- Keep project dependencies up to date with reliable code
- Allow an access to the code anytime, anywhere
- Reduce amount of bugs introduced by accident with maintenance releases.
- Keep tests and experimental code out of releases.
- Allow a feature development to fail without poluting the repository.
To archive all these challenges my main tools are, as you probably know already, Git, CMake and Trac.
Trac for planning ahead
My use of Trac is fairly limited as I use it mainly as a bug tracker but also to write down ideas and plan ahead for the future development and release. I am not really pedentic on which feature will be present for which release. It depends on the work progress of the features and Git is quite an ally for that purpose. I am not an expert in bug trackers and ci and I could probably use another one. Track by itself is great but Track on SF.net is really so slow! I guess a better alternative would be nice.
CMake for cross platform / cross compiler development
CMake is a cross platform project generator. It's good but if one day another similar tool get released, I would definetely have a look expecting a switch. With CMake we define projects and solutions inside script files. Then, CMake generates the project for Visual Studio, GCC/make, XCode, etc. Good in principle but the scripts are quite messy, it's taugh to read someone else scripts, they contains a lot of 'if' for platform specific things, the documentation for build-in functions and variables is ok but for the script language documentation remains limited... Well, it's not perfect, far from it, but for cross platform projects it's a good solution!
With some efforts, CMake gives a certain level of cross platform capabilities of a project. The out of source build feature of CMake allows on a same platform to build multiple project out of the same source code. For example, on a unique platform, a project for Visual Studio 2008, one for Visual Studio 2010, one for GCC, etc. but also multiple projects for different profiles, debug / release, 32 bits / 64 bits. An update of the script and all the projects will be automatically rebuild and updated with the script changes. There are good sides to CMake, definetely!
Git for releases oriented development
Git is a distributed version control system. It has the reputation to be really complicated to use... I would say, it's quite disturbing at the beginning and it requires some thoughts to avoid either a very basic use of it or a complete mess. After few months of use, the experience of CVS and SVN I can say out loud: I LOVE Git!
I like Git for many reasons from which the branch / merge capabilities are on top. One big difference from Git and SVN is that Git manages changes while SVN manages versions. This behavior becomes abvious while using gitk, a GUI program provided with Git which displayes the changes and the relashionship between repository branches. Merging is so easy and so fast (git merge xxx and done) that it is easy to merge several time per working day. Actually, merging often is a good practice to reduce merge conflicts and with Git conflicts could become extremely rare. I actually think that SVN fails with branching, it's because we can't merge often enough.
Git supports repository dependency through a feature call submodule which allows to keep updated external libraries.
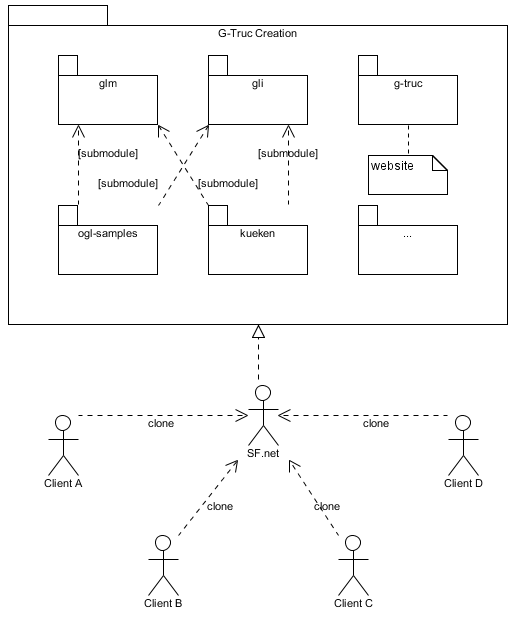
Versions conventions
This is where we actually start to discuss about the releases oriented development model through the release name convensions. My project releases are named and numbered with the following convension: project-name-M.N.P.R.
- M for major
- N for minor
- P for patch
- R for revision
I don't really expect to change the major number. It might happen for a massive update, a rewrite or a change of direction of the project. I actually expect that number to last several years. In a way, this number is a statement for stability expect when it is 0 where if could be seen as a beta release or at least some ongoing development. The minor number is updated for important changes, new main features, possible API changes. I expect this number to change few times a year. This is a statement for depth evolution. The patch number update can involve possible new features but backward compatibility is expected. This number is a statement for improvements and could change a lot of time in a year. The revision number implies mainly bug fixes, compatibility and project maintenance. I expect this number to change anytime, as needed, as much as possible. It's a statement for maintenance.
For any project I want something like these levels of release management and these levels of works. If a critical bug is reported, I need to be able to fix it within a day and release even if I was working on a big new feature, a large rewrite of a project component or even changes that are never going to be released because of a developement failure (result not good enough, technical limitation, etc).
Obviously, this convension has some flexibilities. For example, the major and minor numbers of the OpenGL Samples Pack follows the OpenGL version is supports. Actually the more important concept behind it is the hability of working at various levels of release frequency.
Branches conventions
The releases oriented development model is articulated around 3 types of branches:
- The master branch
- The version branches
- The feature branches
The master branch
The master branch is the name given by Git for what SVN call Trunk. It's the first branch we have when we start a repository. It is a singleton branch used for releases (with tags of each one) and submodules. It's a reliable branch that a user could use if he want to be sure to have the last code revision that works.
The version branches
Version branches is a per-patch branch which life-time is unlimited to ensure that even an old branch could be maintained if needed. When the development of a version is completed and ready for release, the version branch is merged on the master branch and it is tagged. However, if an old version need to be maintained, the old version branch is updated and tag for release directly. Thanks to the amazing merging capabilities of Git and the release oriented developement model, a bug fix in an old branch can easly be apply on all more recent branches with a simple merge.
The feature branches
Finally, the feature branch. It can be created from one version branch but merge to a more recent version branch when completed. It's life time will end and it brings development failure possibility. A feature branch is constantly updated with the older version branch it might be merge to make sure that the code doesn't diverge too much.
This sounds quite complicated? Maybe it is, who knows?! Let's have a look on an example based on the OpenGL Samples Pack. In the real repository, the number of commits is much more higher but I reduce their proportion to see all the connections between branches.
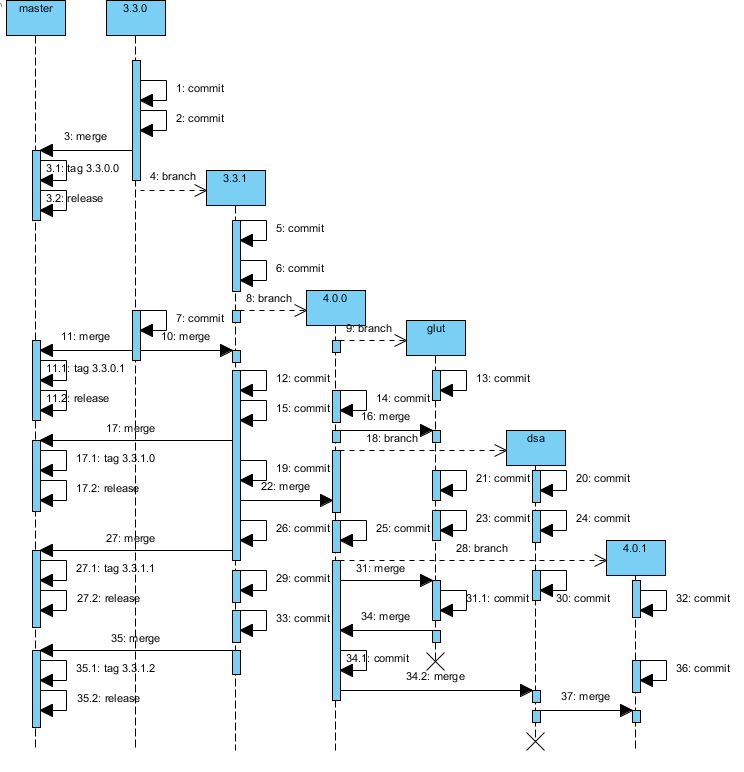
This is actually quite the current state of this project. The OpenGL Samples Pack 3.3.1 is still maintained and any release could be roughly done tomorrow. The development of the OpenGL Samples Pack 4.0.0 is actually finished beside some testings so that the development of the OpenGL Samples Pack 4.0.1 has started. Three versions in parallel, no problem! Also, thanks to the Git submodule, GLM and GLI remained updated to the last version even if I don't actually know with one it's suposed to be. For development clarity, the submodule code is in read only. If I discover a bug in a submodule, I need to update directly in the submodule repository. I might have some improvements to figure out around here... not sure yet.
I am currently quite happy with my working process but still some areas are to investigate. The main topics left are related to the development pipeline and automation.
- Automatic testing and reports
- Automatic packing, daily build
My ultimate goal would be to have a push button, that excutes the tests, provides a reports, tag the release, build an archive with the right filenames and the right version number and update the files. From that I would be not to far from a daily build system. This remains a lot of work to do...