13/01/2011 Compilers performance on SSE code
RSS Feed ~ Comment: by email - on Twitter ~ Share: Twitter - Facebook - Linked In - Google+ - Permanent link
It has been a while since my last compiler performance comparison! Based on my raytracer, which isn't designed to use SSE instructions, I previously highlight that Visual C++ compiler performances were more of less stable, or are even decreasing, since Visual C++ 6 but on the contrary, GCC performances were continuously getting better.
For this new review I decided to take advantages of my work (still in progress) on GLM 0.9.1 regarding SSE optimizations. Just after "Is my optimizations keep this code working?", one of the questions that should always remains while wrtting optimized code is "Is the compiler capable to do a better job than me?" This is not an easy question to answer and ultimately the performance of the optimized code need to be tested against the compiler optimizations. Nevertheless, there are some scenarios where chances are that our optimizations might be really effective: When the optimizations required a specific level of cleverness, equation simplifications, specific data ordering or mathematical rules.
This test is based on various implementations of the computation of a matrix multiplication, a matrix inverse and a matrix determinant. Large arrays of input data are generated and them entirely processed for each operations using prefetches on SSE implementations. On GCC, I used the -O3, -msse2 and -mfpmath=sse optimizations and on Visual C++ /fp:fast, /Ox and /arch:SSE2. -mfpmath=sse and /arch:SSE2 are only used on SSE tests. The compilers tested are Visual C++ 2005 SP1, Visual C++ 2008 SP1, Visual C++ 2010 SP1 Beta and GCC 4.5.1. I did a couple of test with GCC 4.4.0 and the results were pretty much the same as GCC 4.5.1 so that it didn't felt relevant to include these results. 3 different platforms have been used using 3 differents CPU architechture, Core 2 Q6600, Core i5 660 and Phenom II X6 1055T. Without waiting any longer, here is my results:
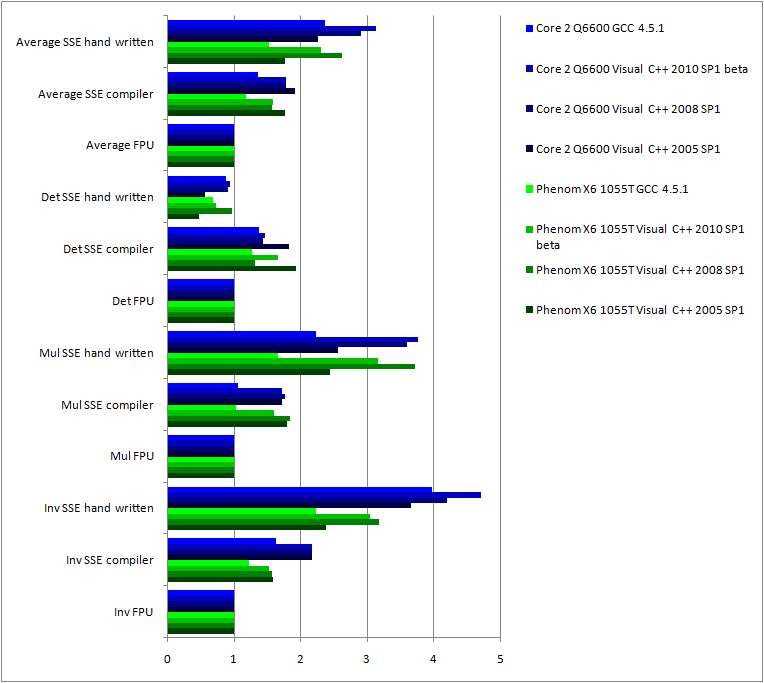
With the proper level of compiler optimizations, the compilers manage to increase the program performances when using SSE instructions. What this chart doesn't show, is that with the default 'release' optimization settings, all Visual C++ versions actually slow down the performances.
Second point, the level of performance reached by the hand written optimizations is really relevant expect on the determinant case... I can go review my copy! Interestingly, Visual C++ seems to make more progresses on optimizations of hand written optimizations with intrinsics than raw C++ code. Visual C++ 2005 seems to have some issues to include hand written optimizations with the rest of the code. However, Visual C++ efficiency to generate SSE code is fairly stable across versions.
It's interesting to see that the behaviour of between the Core 2 and Phenom II processors. I had a look on a Core i5 and the variations are of the same level.
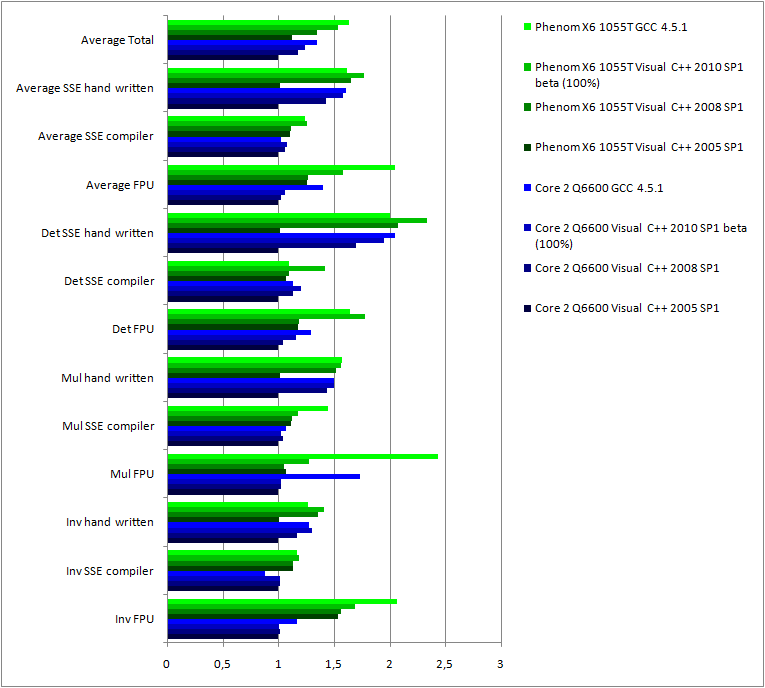
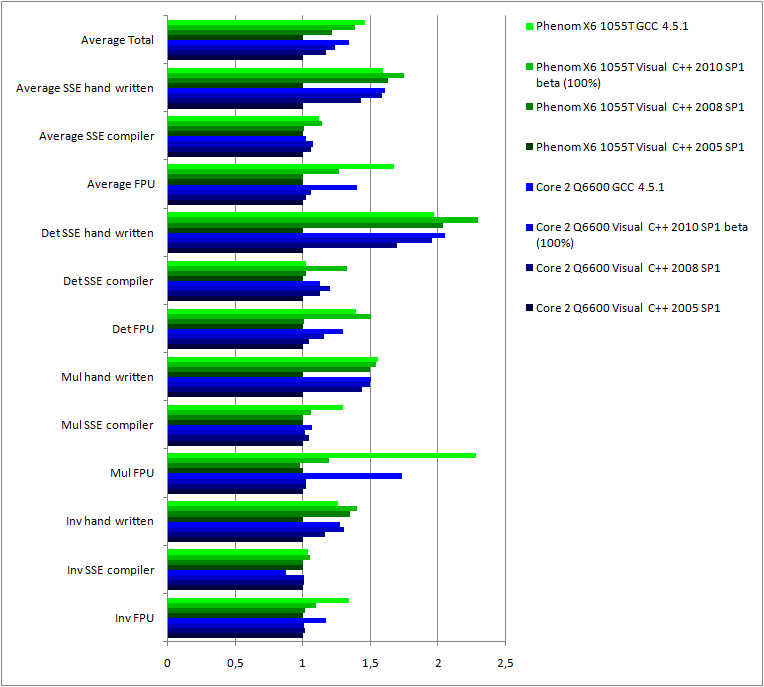
First thing to notice: GCC is astonishingly efficient on FPU optimizations, 50% more efficient than Visual C++ 2010. On hand written optimizations, GCC is on par with Visual C++ 2010 on the Core2 CPU but behind Visual C++ 2008 on the Phenom II CPU. On the regard of generated SSE code, the situation is reversed!
GCC is now a perfectly competitive compiler on term of performances. The performance of Visual C++ are still progressing on SSE code but stable on FPU code.